The way that 3B2 handles structured SGML and XML data is quite unique. Most existing systems require some sort of data filter or transforming process to support their proprietary code. In contrast, 3B2 uses the construction of templates to support a particular DTD or personalised markup (not necessarily XML or SGML) to format the data source on import into the template with no changes to the data itself.
For example in a basic scenario, if we have an element in our instance named <p> we would simply create a style tag in our 3B2 template called 'p' which could contain all of the specific 3B2 processing and formatting information for this particular style. This is then referenced whenever the <p> element occurs in the main text stream and is formatted according to the rules you have set in this style.
Taken to the other extreme, if you were to have XML data you could create only one parent element tag and utilise 3B2's XPath functionality to locate and format the various levels of siblings from this single element.
Below are some of the main benefits of the way 3B2 handles data:
As the data remains unchanged on import, naturally the export of data will preserve the original integrity. With the various output methods of 3B2 including: standard and Unicode text export, direct PDF, XSLT transformations, HTML from screen, amongst others, this makes 3B2 the first choice for any publishing requirement.
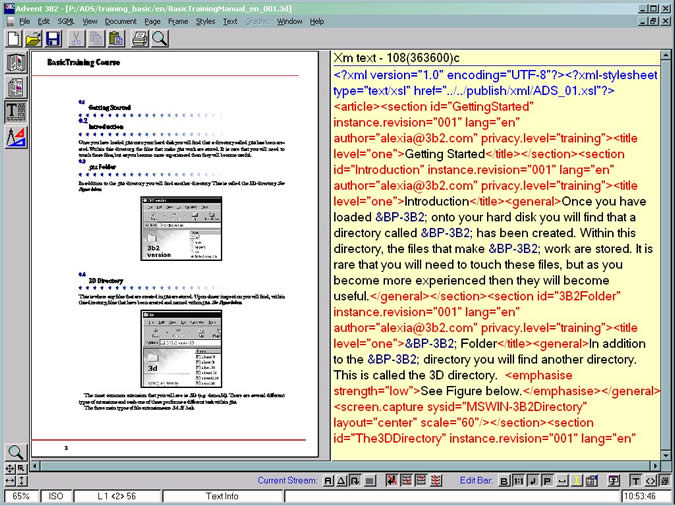
Below is a screen shot of a simple document WYSIWYG view and editbar to the right displaying the source XML data:
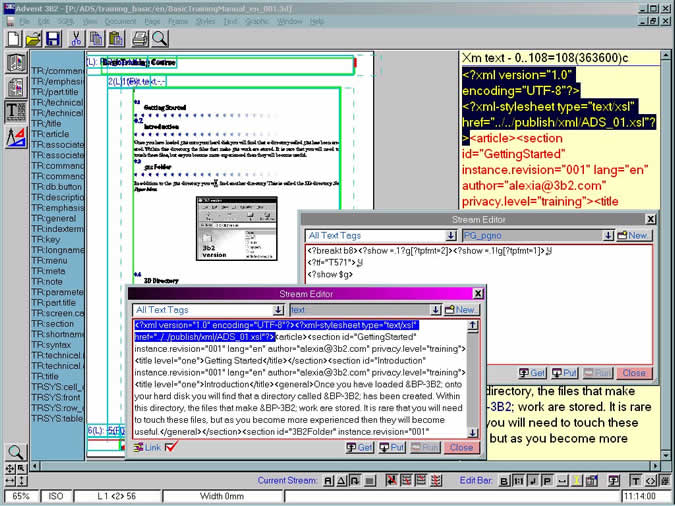
This more complex view of the same document including additional tag editor windows on the bottom right, style tag quick reference blue bar on the left, and displaying document construction frame guides:
See also